
Why NVIDIA Halved the Middle Memory
Inside an AI Server's Memory Stack


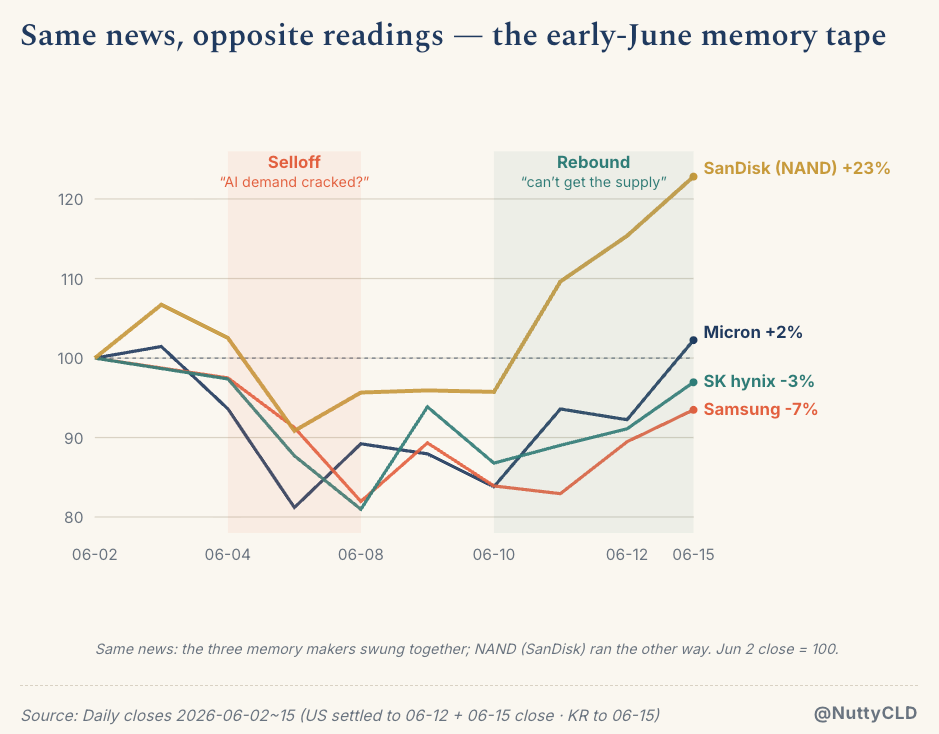
In early June, a single line of news rattled memory stocks for days.
It started on June 4. A paid semiconductor research shop (SemiAnalysis) flagged a change in the memory layout of NVIDIA’s next-generation AI servers: the low-power memory module that sits beside the CPU (SOCAMM) would be halved, from 192GB to 96GB per module. Days later the trade outlet The Elec and the research firm TrendForce reported the same thing, with TrendForce pinning the reason on supply: its estimate is that the three memory makers can deliver only around 60% of what NVIDIA wants in 2027. (Neither NVIDIA nor the memory makers confirmed any of this. It’s reporting, nothing more.)
The market traded the same headline twice. First it dumped memory names, reading the cut as "AI memory demand has finally cracked." A few days later it bought them back: “No, they’re rationing because there isn’t enough to go around.” Micron, SK hynix, and Samsung all plunged and then climbed back.
One thing to settle first: what got cut isn’t all of an AI server’s memory. The ultra-fast memory bolted onto the GPU (HBM) wasn’t touched. What shrank is the low-power memory the CPU uses, off to the side. That’s part of why the same cut split readers two ways.
In the end the two camps were arguing over the temperature of one number: is the shortage cooling, or running hotter? But both missed something. The company that makes and sells this memory, Micron, and the company that buys the most of it, NVIDIA, wrote opposite signals into their own official materials. Not a leak or a guess; it’s in documents the two companies published themselves.
The seller says “pack in more.” The buyer cut it in half.
Micron, which makes and sells this memory, has long said: pack in more. In its own technical white paper it lays out, with benchmark numbers, how much faster AI inference runs as you add more of it. When an AI reads a long passage and answers, the model has to hold the context it has read so far somewhere. (The industry calls this temporary memory the “KV cache,” a scratchpad that saves what’s already been read so it doesn’t have to be recomputed each time.) Micron’s pitch: the more generously you line that space with the low-power memory it makes, the faster the responses. The conclusion is plain: more is better, and there’s room for more.
And yet NVIDIA, which will buy more of that memory than anyone, went the other way. In its flagship next-gen server it cut exactly that memory in half.
The seller says add more; the buyer says it'll use less and redesigns the server around that. Who's right? Usually the one who actually designs the machine out of the parts knows what it needs better than the one selling the parts. NVIDIA knows what its own servers need better than anyone. When a company like that moves against its supplier's advice, it means there's something "too little" or "too much" can't explain.
It’s because NVIDIA is solving a different problem. Where Micron asks “does adding more of this memory help?”, NVIDIA asks “where and how should memory sit to deliver the same performance at the lowest cost and the least power?” And the answer wasn’t “stack more of one kind.”
So the real question isn’t “has the shortage cooled.” Where did NVIDIA move the work that memory used to do? Find that spot, and you can see which tier the money flows to next.